
System: Avoiding duplicate content filters
Since late 2004 Google has been cracking down hard on so-called 'duplicate content'. Their motive: to penalise sites that contain little or no unique content but 'scrape' text from other sites and search engine results pages (SERP), usually with the aim of making money through advertising.
A side-effect of this has been that a huge number of other sites have fallen into the trap. This is typically because they allow pages to be accessed through more than one address, but also where the content of different pages is deemed 'too similar' by the search algorithm.
How to tell if you have duplicate content
The first step in identifying the problem is to do a Google search for pages on your site:
site:example.net
site:www.example.net
If you see a lot of pages listed as 'Supplemental Result' then you could well be affected. You need to examine the pages that appear with that flag to see if there is an obvious duplicate content or duplicate address problem. If it's the content that has problems (duplicate TITLEs, META description, headings, text, etc.) then the pages need to be re-written.
If it's the address that has the problem - more than address brings up the exact same page - then you need to do some rewriting. A number of common causes are described below. In each case the solution is to set up a 301 (Permanent) redirect from the unwanted address(es) to take browsers, and more importantly spiders, to the correct address.
After making such a change you can expect to wait at least a week and maybe longer to see the affect in SERPs, but you can (and should) also monitor the affect by analysing your log files to see which requests are being redirected - particulary from search engine spiders.
Unifying the domain name
One very common problem is with domains that are accesssible both with- and without the 'www.' prefix on the domain name. For example:
http://www.example.net/
http://example.net/
While it's good practice to have both addresses bring up your website, you need to set up rewrite rules (using mod_rewrite) to restrict browsers and search engine spiders to just one.
This is done using the following rewrite rule:
RewriteCond %{HTTP_HOST} !^www\.example\.net$ [NC]
RewriteRule (.*) http://www.example.net/$1 [R=301,L]
Translation:
- IF the domain is not www.example.net;
- THEN redirect to the same page at the desired domain.
The opposite case - if you want to settle on not having the 'www.' prefix - is as follows:
RewriteCond %{HTTP_HOST} !^example\.net$ [NC]
RewriteRule (.*) http://example.net/$1 [R=301,L]
The same rules will work for sites that have different top level domains (TLDs) pointing to the same site. eg. example.com and example.net. You need to decide again which one you want to be the 'primary' domain name.
Unifying page addresses
If a page has been indexed both as folder and folder/ then you need to set up a rule to add the slash / to the address when it's missing:
RewriteRule ^folder$ /folder/ [R=301,L]
Depending on your site structure you may be able to apply this to multiple addresses by using a regular expression.
eg. for specific addresses:
RewriteRule ^(folder1|folder2|folder3)$ /$1/ [R=301,L]
or for all:
RewriteRule ^([a-z]+)$ /$1/ [R=301,L]
Exactly the same principles apply for pages that have been indexed with- and without an extension, which can happen if you're have Content Negotiation enabled and make a mistake with one of your links:
RewriteRule ^page$ /page.html [R=301,L]
Removing query strings
In some cases the same page can be indexed multiple, even up to hundreds of times, with varying query strings (GET parameters). In some cases this is by design:
http://www.example.net/article.php?id=1
http://www.example.net/article.php?id=2
...
Note: If you're using this style of addressing on your site then you may want to read further about creating Search Engine Friendly URL's.
but in others can be a problem:
http://www.example.net/?ref=abc
http://www.example.net/?ref=def
http://www.example.net/?ref=wxy
Something as simple as this can quickly 'pollute' your presence in search engine results, but the fix is also quite simple:
RewriteCond %{QUERY_STRING} ^ref=
RewriteRule (.*) /$1? [R=301,L]
Note: The ? in the RewriteRule is not a regular-expression pattern, but rather represents a 'NULL' query string.
Translation:
- IF the query string starts with ref=;
- THEN redirect to the same page with the query string removed.
If you're using the query string to track referrals from affiliated sites then you should use a server-side script to FIRST record the details (in a database or using cookies) and THEN issue a 301 Permanent Redirect. The method above will remove the query string BEFORE calling any scripts.
Secure (HTTPS) and non-secure pages
If you have an SSL certificate for your site and use https for some pages (a checkout page for example) then often the secure status is maintained when people (or search engine spiders) navigate away from there and back to the main site, resulting in duplicate content.
The first step is to decide which pages need to be secured and enforce this using mod_rewite rules. This means forcing those pages to appear under https and other pages to appear under http.
Here's a real life example (both rules are used):
RewriteCond %{SERVER_PORT} 80
RewriteRule ^(cart|checkout|complete) https://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
Translation:
- IF the request is not secure (using port 80);
- AND the requested page starts with 'cart', 'checkout' or 'complete' (three separate pages);
- THEN redirect to the same address using https (port 443).
RewriteCond %{SERVER_PORT} 443
RewriteCond %{REQUEST_URI} !^/(images|style|robots)
RewriteRule !^(cart|checkout|complete) http://%{HTTP_HOST}%{REQUEST_URI} [R=301,L]
Translation:
- IF the request is secure (using port 443);
- AND the request doesn't start with /images, /style or /robots;
- AND the requested page doesn't start with 'cart', 'checkout' or 'complete';
- THEN redirect to the same address using http (port 80).
The second RewriteCond is used to exclude files such as images and style sheets that need to be included by the secure page(s) and therefore need to be accessible over port 443. Also we want search engines to be able to access the robots.txt file.
The examples presented above are very much site-specific. For your own site you will have different filenames and different requirements. Hopefully you can work out the correct rules for your site based on these examples. And don't forget to monitor the logfiles to see what effect they're having.
Even with the redirects in place you should try to set up the site so that they aren't triggered by normal browsing, and also add rel="nofollow" attributes to links to pages such as 'checkouts' that have no value to search engines. For spiders that don't suppor the rel attribute, use a META robots tag marking those pages as noindex,follow.
Problems with multiple redirects
Google's spider, Googlebot, seems to have a problem when multiple 301 Redirects occur in response to a page request.
For example:
https://www.example.com/product/12345
301 Redirect => http://www.example.com/product/12345 ( switch to non-secure )
301 Redirect => http://www.example.com/product/12345.html ( add HTML extension )
If you have two or more permanent redirects as shown, you might find that the old addresses are never removed from the Google index and instead continue to show up as Supplemental Results. Yahoo! and MSN seem to do a bit better in this specific case.
Both Slurp and Googlebot have a similar problem when a 301 Redirect leads to a 404 Not Found - the first address is never removed from their respective indexes.
For example:
http://www.example.com/product/12345
301 Redirect => http://www.example.com/product/12345.html ( add HTML extension )
404 Not Found
It's not clear what the best approach is to take in these situations - especially as the spidering algorithms are constantly evolving. Perhaps removing the second redirect until Google 'catches up', but that isn't always practical. Other options are to change one of the redirects to 302 Found instead of 301 Permanent Redirect, or to hard-code redirects for each affected page either using mod_rewrite or from within your server-side scripts.
If you're tempted to send different responses to the spiders than to normal visitors then be very careful. You might jump out of the 'duplicate content' pot only to find yourself in the 'cloaking' fire which is much harder to get away from.
Note: if you're not sure what your site is sending in response to a page request, try using Rex Swain's HTTP Viewer linked under References below.
Every domain needs robots.txt
Another way to combat Supplemental Result fever is to deliver a different robots.txt file for domains that you don't want indexed. The file you want spiders to see in this case is:
User-agent: *
Disallow: /
Note: save this file as no-robots.txt for the following to make sense.
This can be tricky if all the domains point to the same location on the server, but a couple of rewrite rules can help:
Prevent indexing of HTTPS pages:
RewriteCond %{SERVER_PORT} 443
RewriteRule ^robots.txt /no-robots.txt
Prevent indexing of unwanted domains:
To prevent indexing of pages with domains other than your 'primary' domain requires a slighly different rule, and an extra RewriteCond to the rules presented earlier.
RewriteCond %{HTTP_HOST} !^www\.example\.com
RewriteRule ^robots\.txt /no-robots.txt [L]
RewriteCond %{HTTP_HOST} !^www\.example\.com$
RewriteCond %{REQUEST_URI} !^/no-robots\.txt
RewriteRule (.*) http://www.example.com/$1 [R=301,L]
One rule to bind them:
If your site is having problems both with HTTPS pages being indexed and with multiple domains then the above rules can be merged into one.
RewriteCond %{SERVER_PORT} 443 [OR]
RewriteCond %{HTTP_HOST} !^www\.example\.com
RewriteRule ^robots\.txt /no-robots.txt [L]
RewriteCond %{HTTP_HOST} !^www\.example\.com$
RewriteCond %{REQUEST_URI} !^/no-robots\.txt
RewriteRule (.*) http://www.example.com/$1 [R=301,L]
Note: if you're also using the 443 to 80 redirect presented earlier then you need to also replace robots in the second RewriteCond with no-robots.
The end result that we're aiming for is shown in the graphic below, with the arrows representing 301 redirects between different domains. Notice that we no longer redirect requests for robots.txt which keeps the search engines happy, but still issue redirects for normal and secure content pages and files:
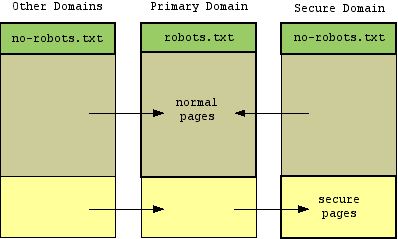
What the bold outlines are trying to show in this diagram is that there is now only one domain under which a given webpage can be accessed (one for secure pages and another for non-secure), but every domain has a robots.txt file with all but the primary domain set to disallow all spiders.
Don't forget to ensure that images, style sheets and any other included files are accessible through both HTTP and HTTPS for your secure site to work properly.
References
Related Articles - mod_rewrite
- System mod_rewrite: Examples
- System Using mod_rewrite to canonicalize and secure your domain
- System Avoiding duplicate content filters
- System Saving bandwidth with mod_rewrite and ImageMagick
- System mod_rewrite: Seach Engine Friendly URL's